历史文献中的“态度”
历史文献中的“态度”
近期在针对二十四史进行语料库建设,在训练词向量的过程中,发现针对同一个词,不同的文献训练出的相似词带有明显的情感 倾向,比较有意思,记录如下。
一、 文本整理与词向量训练
本文中训练词向量采用的是python的gensim包,针对二十四史分别与公共新闻文本库混合进行训练。这样可以既可以满足训练所需要的 大文本要求,又能避免不同历史文献同名词汇的相互干扰。训练过程采用了skip-gram 算法,窗口宽度为10,100维向量空间。词向量的 概念此处不予详细解说,可参考 word2vec 。
二、 不通文献对人物的态度 汉代的历史人物,其人物事迹、历史形象为人们广为熟知,我尝试选取《汉书》、《后汉书》、《三国志》、《史记》四本书,对比研究几个主要 历史人物的前100个近似词,以期能够看出不同文本在叙述同一历史人物时在书写上的倾向性。
1、刘邦
《汉书》

《后汉书》

《三国志》

《史记》

以上针对“刘邦”的词向量比对,可以看出不同历史文本在叙事描述上的主观倾向性。
其中成书于东汉的《汉书》中,与“刘邦”关系最近的词汇中, 褒义词和正面描述词汇极多,其中关系最近的词汇是“高祖”,其次“行赏”、“重建”、“崛起”、“盛名”、“神庙”等词汇近似度极高。 且词汇所表现的历史事件多集中在汉朝建立前。
从《后汉书》的分析结果来看,与“刘邦”一词关系接近的词汇和《汉书》基本一致,表明在叙事上面并没有大的改变,但是词汇中出现了更多 的明显表现汉帝国成立以后的叙事词汇。
《三国志》中反映出来的相关词汇则显示了大量的贬义、负面情绪的词汇,展示了作者叙事情绪对比两汉书时的反转。
成书最早的《史记》则表现出了最客观的态度,强相关词汇以关键地名和名词为主,从相关词中能够基本了解到刘邦政治生涯中的关键事件和关键地点。
类似的情绪倾向可以参考比对其他关键词进行思考,可以提示一些有意思的看法。如 “项羽”、“韩信”。
其中“韩信”一次,可以从词向量亲疏关系中明显看出,在两汉书中,韩信的故事叙述主要和同时期同等地位的人相提并论,而《史记》中则主要放到与两大 政治集团首领:刘邦、项羽的叙事故事中进行描述, 在《三国志》中,与“韩信”关系极近的词,由人名变成了地名和大量的描写心理的词汇,如“疑惑” 、“羞愧”、“稳重”、“迟疑”、“无能为力”、“随机应变”等,暗示着在三国志中提到“韩信”时,韩信已不再作为故事主人翁被讲述,而是用于比较参考的一个对象。 回到原书中进行比较阅读,确实如此。
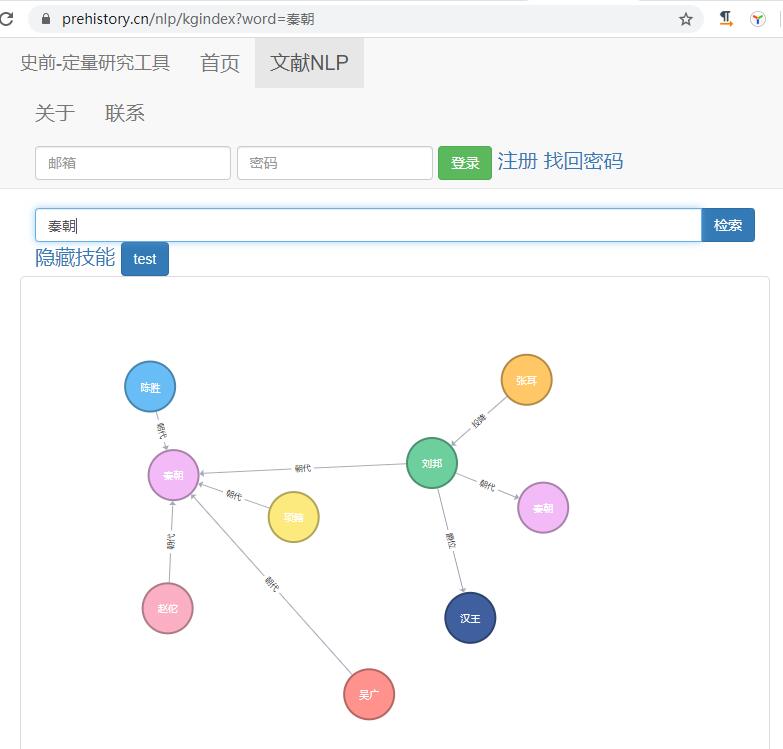
词向量的查询工具已经发布到 史前,可以拿自己感兴趣的词进行尝试。后续会逐步完成全部二十四史的词向量模型。